실험계획법(design of experiments) - 실험에 대한 설계 및 분석방법
품질 및 공정최적화를 위해서 어떻게 실험을 행하고, 데이터를 어떻게 취하며, 어떠한 통계적 방법으로 데이터를 분석할 것인가를 계획하는 것
11.1 실험계획의 기본개념
11.1.1 인자 및 수준
인자(factor) - 제품 등의 품질이나 공정에 영향을 주는 주요 요인으로 판단되어 실험에서 관심의 대상이 되는 변수
해당 인자에 대해 몇 가지로 나뉘는 실험조건, 즉 인자를 양적 또는 질적으로 변화시킬 경우의 단계를 그 인자의 수준(level)이라고 함
이 때 인자들의 각 수준들의 조합을 수준조합 또는 처리조건(treatment)라 부름
11.1.2 교호작용
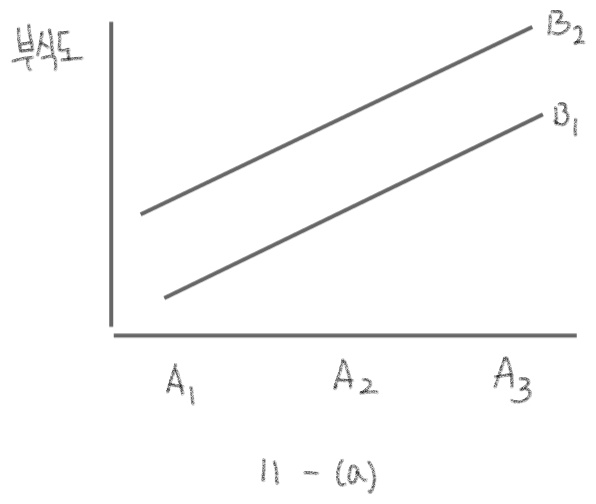
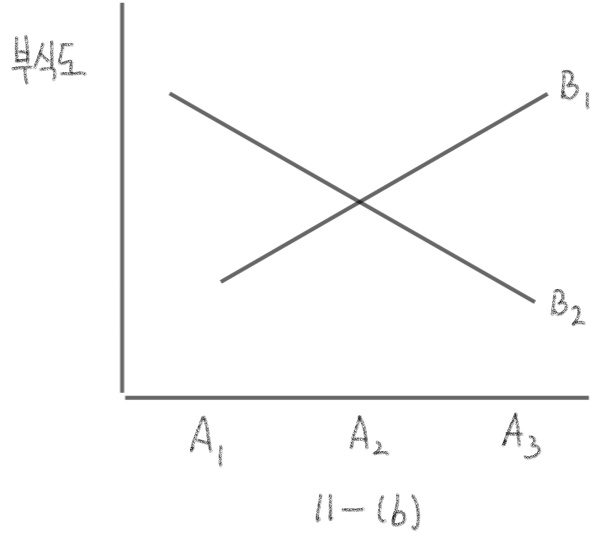
어떤 품질요인으로 다수의 인자가 관여될 수 있으며 또한 두 개 이상의 인자를 취급할 때는 두 인자 간의 교호작용(interaction)이 있을 수 있음
한 인자의 수준에 따른 종속변수의 변화가 다른 인자의 수준에 따라 다르게 나타날 때, 두 인자 간의 교호작용이 있다고 함
예를 들어 알루미늄 부식에 코팅방식(A인자)와 습도(B인자)의 두 인자가 영향을 준다고 가정할 때
코팅방식의 세 수준(각각 A 1 , A 2 , A 3 A_1, A_2, A_3 A 1 , A 2 , A 3 B 1 , B 2 B_1, B_2 B 1 , B 2
(A 3 , B 2 A_3, B_2 A 3 , B 2 A 1 , B 1 A_1, B_1 A 1 , B 1
두 인자 간의 교호작용이 있는 경우 11-(b)와 같은 형태를 보임
11.1.3 실험계획법의 종류
주요 실험계획법으로는 다음과 같은 방법들이 있다.
일원배치법(single factor design)
한 인자의 영향을 조사하기 위한 실험계획법
일원배치법은 각 실험처리에 대해 실험단위를 완전히 랜덤하게 배치하여 실험하는 방법이므로 완전무작위계획법(completely randomized design)이라고도 함이원배치법(two-factor design)
두 개의 인자에 대해 그 영향을 조사할 때 쓰이는 방법
각 인자의 수준 수는 다를 수 있으며 모든 수준조합에 대해 실험을 진행
이 때 각 수준조합에 대해 반복적으로 실험을 행할 수도 있음
이원배치법을 확장하여 두 개 이상의 인자를 포함한 실험을 다원배치법이라 함요인배치법(factorial design) 각 인자의 수준수를 동일하게 설계하여 실험을 행하는 방법
인자수가 n개 있고 각 인자의 수준이 2라면 2 n 2^n 2 n 3 n 3^n 3 n
일부실시법(fractional factorial design)
각 인자의 수준조합 중에서 일부만 선택하여 실험횟수를 가능한 적게 하는 방법
대신 불필요한 교호작용은 분석하지 않음
11.1.4 실험계획법의 순서
실험연구는 실험목적의 정의, 실험계획, 실험의 진행, 자료의 분석, 결과의 해석의 과정을 거침
세부적인 단계를 아래와 같다
1단계: 실험목적을 설정하고 구체적인 문제를 정의하며 연구가설을 세움
2단계: 실험목적에 따른 반응치 설정. 이 때 측정가능성 및 반응치에 대한 타인자의 영향은 없는지 고려
3단계: 인자와 인자의 수준을 결정. 인자의 수준을 나눌 때는 실험에 드는 시간 및 비용도 고려해야함
4단계: 실험의 배치방법과 실험순서를 정함. 실험장비의 배치는 실험이 용이하고 외부환경의 영향을 통제할 수 있도록 해야함. 실험순서에 민감한 실험인 경우에는 무작위로 실험순서를 정해야 함
5단계: 실험 실시. 예비 실험을 통해 실험방법을 보완할 수도 있음
6단계: 데이터를 분석하고 결과 해석. 인자의 유의성을 판정하기 위해서는 주로 분산분석법을 사용하며, 필요시 수준조합별 평균의 점추정 또는 신뢰구간을 산출.
결측치는 분석 전에 미리 적절한 조치를 취해주어야함
품질 또는 공정 최적화를 목적으로 행한 실험의 경우 영향인자를 추출하고 최적 수준조합을 도출
11.2 일원배치법
인자가 하나인 실험에 대한 설계를 일원배치법이라 함
인자의 수준수가 a a a r r r a r ar a r
인자 A의 수준이 a개 이고, 각 수준에서 반복수가 r일 때 일원배치법에 의한 i번째 수준에서 j번째 반복으로부터 얻어진 실험결과치를 Y i j Y_{ij} Y ij
Y i j = μ i + ε i j , i = 1 , 2 , , j = 1 , 2 , … , r μ i = μ + α i (11.1) \tag{11.1}
\begin{align*}
Y_{ij} &= \mu_i + \varepsilon_{ij}, \,\,i = 1, 2, \,\,, j = 1, 2, \dots, r \\
\mu_i &= \mu + \alpha_i
\end{align*}
Y ij μ i = μ i + ε ij , i = 1 , 2 , , j = 1 , 2 , … , r = μ + α i ( 11.1 ) 여기서 μ i \mu_i μ i
이는 다시 전체평균 μ \mu μ α i \alpha_i α i
수준에 따라 평균이 다르다는 것은 α i \alpha_i α i
어떤 수준 i에서 평균이 전체 평균(μ \mu μ α i > 0 \alpha_i > 0 α i > 0
어떤 수준 j에서 평균이 전체 평균보다 작으면 α j < 0 \alpha_j < 0 α j < 0
따라서 ∑ α i = 0 \sum \alpha_i = 0 ∑ α i = 0
오차항 ε i \varepsilon_i ε i σ 2 \sigma^2 σ 2
i번째 수준의 (표본)평균 Y ˉ i \bar Y_i Y ˉ i Y ˉ \bar Y Y ˉ
Y ˉ i = 1 r ∑ j = 1 r Y i j = T i r , i = 1 , 2 , … , α Y ˉ = 1 a r ∑ i = 1 α ∑ j = 1 r Y i j = T a r \begin{align*}
\bar Y_i &= \frac{1}{r}\sum_{j=1}^{r}Y_{ij} = \frac{T_i}{r}, \,\, i = 1, 2, \dots, \alpha \\
\bar Y &= \frac{1}{ar}\sum_{i=1}^{\alpha}\sum_{j=1}^{r}Y_{ij} = \frac{T}{ar}
\end{align*}
Y ˉ i Y ˉ = r 1 j = 1 ∑ r Y ij = r T i , i = 1 , 2 , … , α = a r 1 i = 1 ∑ α j = 1 ∑ r Y ij = a r T <표 11-1> 일원배치법의 데이터구조
인자의 수준 실험의 반복 A 1 A 2 … A n Y 11 Y 21 … Y a 1 Y 12 Y 22 … Y a 2 ⋮ ⋮ ⋮ Y 1 r Y 2 r … Y a r \begin{matrix}A_1&&A_2&&\dots&&A_n\\Y_{11}&&Y_{21}&&\dots&&Y_{a1}\\Y_{12}&&Y_{22}&&\dots&&Y_{a2}\\\vdots&&\vdots&&&&\vdots\\Y_{1r}&&Y_{2r}&&\dots&&Y_{ar}\end{matrix} A 1 Y 11 Y 12 ⋮ Y 1 r A 2 Y 21 Y 22 ⋮ Y 2 r … … … … A n Y a 1 Y a 2 ⋮ Y a r 합/평균 T 1 T 2 … T a Y ˉ 1 Y ˉ 2 … Y ˉ a \begin{matrix}T_1&&T_2&&\dots&&T_a\\\bar Y_1&&\bar Y_2 &&\dots&&\bar Y_a\end{matrix} T 1 Y ˉ 1 T 2 Y ˉ 2 … … T a Y ˉ a T Y ˉ \begin{matrix}T\\\bar Y\end{matrix} T Y ˉ
관심사는 인자 A의 수준을 변화시킬 때 평균반응치가 변하는 지 여부
인자수준이 변할 때 반응치가 심하게 변할수록 그 인자가 큰 영향을 준다고 할 수 있음
인자수준이 변해도 반응치가 변하지 않으면 그 인자는 영향요인이 아니라고 할 수 있음
수준별 평균(μ i \mu_i μ i α i \alpha_i α i
따라서 다음과 같은 가설을 검정하고자 함
H 0 : α 1 = α 2 = ⋯ = α α = 0 H 1 : α i ≠ 0 (11.2)
\tag{11.2}
\begin{aligned}
H_0 &: \alpha_1 = \alpha_2 = \dots = \alpha_{\alpha} = 0 \\
H_1 &: \alpha_i \neq 0
\end{aligned}
H 0 H 1 : α 1 = α 2 = ⋯ = α α = 0 : α i = 0 ( 11.2 )
귀무가설 H 0 H_0 H 0
식 11.2 의 가설을 검정하기 위해 다중회귀분석에서 F검정하는 방법과 유사한 방법 사용
즉 오차항의 분산 σ 2 \sigma^2 σ 2
H 0 H_0 H 0 σ 2 \sigma^2 σ 2 H 0 H_0 H 0 σ 2 \sigma^2 σ 2
이를 위해서 우선 회귀분석에서와 마찬가지로 전체제곱합을 분해하여야 함
전체제곱합(SST)는 다음과 같이 오차제곱합(잔차제곱합)과 인자 A에 의한 제곱합으로 나눌 수 있다
∑ i ∑ j ( Y i j − Y ˉ … ) 2 = r ∑ i ( Y ˉ i − Y ˉ … ) 2 + ∑ i ∑ j ( Y i j − Y ˉ i … ) 2 (11.3)
\tag{11.3}
\sum_i\sum_j(Y_{ij} - \bar Y \dots )^2 = r\sum_i(\bar Y_i - \bar Y \dots)^2 + \sum_i\sum_j(Y_{ij} - \bar Y_{i}\dots)^2
i ∑ j ∑ ( Y ij − Y ˉ … ) 2 = r i ∑ ( Y ˉ i − Y ˉ … ) 2 + i ∑ j ∑ ( Y ij − Y ˉ i … ) 2 ( 11.3 )
총제곱합(SST) = 인자 A의 제곱합(SSA) + 오차제곱합(SSE)
SSA는 인자 A의 각 수준에서의 평균과 전체 평균과의 차의 제곱합으로 자유도 (a-1)
SSE는 서로 독립인 a개의 수준에서 각 관측값과 수준평균과의 차의 제곱합
한 수준내의 자유도가 각각 r-1이 되어 SSE의 자유도는 a(r-1)
따라서 평균제곱은 다음과 같이 각각의 제곱합을 자유도로 나눈 값이다
인자 A 평균제곱 MSA = SSA /(a-1)
오차평균제곱 MSE = SSE/a(r-1)
여기서 MSE는 가설과 관계없이 항상 σ 2 \sigma^2 σ 2 H 0 H_0 H 0 σ 2 \sigma^2 σ 2
식 11.3에서 SSA를 구하기 위해 Y ˉ i \bar Y_i Y ˉ i Y ˉ \bar Y Y ˉ H 0 H_0 H 0 ( Y ˉ i − Y ˉ ) (\bar Y_i - \bar Y) ( Y ˉ i − Y ˉ )
따라서 식 11.2의 가설에 대한 검정통계량은 다음과 같다
F = M S A M S E (11.4)
\tag{11.4}
F = \frac{MSA}{MSE}
F = MSE MS A ( 11.4 ) 식 11.4에 의해 구한 F값이 1보다 매우 크다는 것은 MSA가 MSE와는 상당히 다른 값을 갖는 것을 의미하므로 MSA를 σ 2 \sigma^2 σ 2 H 0 H_0 H 0
검정통계량 F는 가설 H 0 H_0 H 0 H 0 H_0 H 0
F > F ( α ; a − 1 , a ( r − 1 ) )
F > F_{(\alpha;\, a-1,a(r-1))}
F > F ( α ; a − 1 , a ( r − 1 )) 여기서도 F값이 1보다 큰 경우만 관심에 두기 때문에 단측검정에 해당
회귀분석에서와 같이 F값에 대응한 p값이 산출되면 보다 용이하게 다앙한 유의수준에서 검정 실시 가능
이와 같은 과정을 정리하면 아래 표 11-2와 같은 분산분석표로 요약할 수 있음
<표 11-2> 일원배치법의 분산분석표
변동요인 자유도 제곱합 평균제곱 F − F- F − 인자 A a − 1 a-1 a − 1 S S A SSA SS A M S A MSA MS A F = M S A / M S E F=MSA/MSE F = MS A / MSE 오차 a ( r − 1 ) a(r-1) a ( r − 1 ) S S E SSE SSE M S E MSE MSE 전체 a r − 1 ar-1 a r − 1 S S T SST SST
11.3 이원배치법
두 개의 인자를 취해 실험을 하는 방법
두 개의 인자 A와 B의 수준들의 조합에 대한 실험을 하여 각 인자의 영향을 조사하는 것
11.3.1 반복이 없는 이원배치법
인자 A의 수준이 a개 이고 인자 B의 수준이 b개일 때 모든 실험처리조합에 대해서 한번씩의 실험을 행하는 경우
반복이 없는 이원배치법의 데이터 구조식은 다음과 같음
Y i j = μ i j + ε i j , i = 1 , 2 , … , a ; j = 1 , 2 , … , b ; (11.5)
\tag{11.5}
Y_{ij} = \mu_{ij} + \varepsilon_{ij}, \,\,i= 1,2,\dots, a; \,\, j = 1,2,\dots,b;
Y ij = μ ij + ε ij , i = 1 , 2 , … , a ; j = 1 , 2 , … , b ; ( 11.5 ) μ i j = μ + a i + b j
\mu_{ij} = \mu + a_i + b_j
μ ij = μ + a i + b j
μ i j \mu_{ij} μ ij
μ \mu μ
a i a_i a i
b j b_j b j
<표 11-3> 반복이 없는 이원배치법의 데이터 구조
인자 B \ 인자 A A 1 A 2 … A a \begin{matrix}A_1&&A_2&&\dots&&A_a\end{matrix} A 1 A 2 … A a 합 평균 B 1 B 2 ⋮ B b \begin{matrix}B_1\\B_2\\\vdots\\B_b\end{matrix} B 1 B 2 ⋮ B b Y 11 Y 21 … Y a 1 Y 12 Y 22 … Y a 2 ⋮ ⋮ ⋮ Y 1 b Y 2 b … Y a b \begin{matrix}Y_{11}&&Y_{21}&&\dots&&Y_{a1}\\Y_{12}&&Y_{22}&&\dots&&Y_{a2}\\\vdots&&\vdots&&&&\vdots\\Y_{1b}&&Y_{2b}&&\dots&&Y_{ab}\\\end{matrix} Y 11 Y 12 ⋮ Y 1 b Y 21 Y 22 ⋮ Y 2 b … … … Y a 1 Y a 2 ⋮ Y ab T 1 T 2 ⋮ T b \begin{matrix}T_1\\T_2\\\vdots\\T_b\end{matrix} T 1 T 2 ⋮ T b Y ˉ 1 Y ˉ 2 ⋮ Y ˉ b \begin{matrix}\bar Y_1\\\bar Y_2\\\vdots\\\bar Y_b\end{matrix} Y ˉ 1 Y ˉ 2 ⋮ Y ˉ b 합 T 1 T 2 … T a \begin{matrix}T_1&&T_2&&\dots&&T_a\end{matrix} T 1 T 2 … T a T T T 평균 Y ˉ 1 Y ˉ 2 … Y ˉ a \begin{matrix}\bar Y_1&&\bar Y_2&&\dots&&\bar Y_a\end{matrix} Y ˉ 1 Y ˉ 2 … Y ˉ a Y ˉ \bar Y Y ˉ
여기서 관심사는 인자 A의 수준 변화에 따라 반응치에 차이가 있는지, 인자 B의 수준변화에 따라 반응치에 차이가 있는지 여부
이를 다음과 같은 귀무가설로 표현할 수 있음
H 0 A : α 1 = α 2 = ⋯ = α a = 0 (11.6a)
\tag{11.6a}
H_{0A} : \alpha_1 = \alpha_2 = \dots = \alpha_a = 0
H 0 A : α 1 = α 2 = ⋯ = α a = 0 ( 11.6a ) H 0 B = β 1 = β 2 = ⋯ = β b = 0 (11.6b)
\tag{11.6b}
H_{0B} = \beta_1 = \beta_2 = \dots = \beta_b = 0
H 0 B = β 1 = β 2 = ⋯ = β b = 0 ( 11.6b ) 이 가설을 검정하기 위해 분산분석표 작성 필요
전체제곱합은 다음과 같이 분해할 수 있음
S S T = ∑ i = 1 a ∑ j = 1 b ( Y i j − Y ˉ . . ) 2 = ∑ i ∑ j ( Y ˉ i . − Y ˉ . . ) 2 + ∑ i ∑ j ( Y ˉ . j − Y ˉ . . ) 2 + ∑ i ∑ j ( Y i j − Y ˉ i . − Y ˉ . j + Y ˉ . . ) 2 = S S A + S S B + S S E
\begin{aligned}
SST &= \sum_{i=1}^a \sum_{j=1}^b (Y_{ij} - \bar Y ..)^2 \\
&= \sum_i \sum_j (\bar Y_{i.} - \bar Y..)^2 + \sum_i \sum_j (\bar Y_{.j} - \bar Y ..)^2 + \sum_i \sum_j (Y_{ij}-\bar Y_{i.} - \bar Y_{.j}+\bar Y..)^2 \\
&= SSA + SSB + SSE
\end{aligned}
SST = i = 1 ∑ a j = 1 ∑ b ( Y ij − Y ˉ .. ) 2 = i ∑ j ∑ ( Y ˉ i . − Y ˉ .. ) 2 + i ∑ j ∑ ( Y ˉ . j − Y ˉ .. ) 2 + i ∑ j ∑ ( Y ij − Y ˉ i . − Y ˉ . j + Y ˉ .. ) 2 = SS A + SSB + SSE
여기서 SSA는 인자 A의 제곱합 - 관련 자유도는 (a-1)
SSB는 인자 B의 제곱합이며 관련 자유도 (b-1)
일원배치법과 유사한 방법으로 평균제곱을 산출하고 분산분석표를 작성하면 다음 표와 같음
<표 11-4> 반복이 없는 이원배치법의 분산분석표
변동요인 제곱합 자유도 평균제곱 F-값 인자 A SSA a-1 MSA=SSA/(a-1) F A F_A F A 인자 B SSB b-1 MSB=SSB/(b-1) F B F_B F B 오차 SSE (a-1)(b-1) MSE=SSE/(a-1)(b-1) 전체 SST ab-1
MSE는 가설과 관계없이 σ 2 \sigma^2 σ 2
MSA는 식 11.6a의 가설 H 0 A H_{0A} H 0 A σ 2 \sigma^2 σ 2 H 0 B H_{0B} H 0 B σ 2 \sigma^2 σ 2
따라서 다음 두 개의 F-값을 산출하여 유의수준에 대해 가설을 검정함
F A > F ( α ; a − 1 , ( a − 1 ) ( b − 1 ) ) 이면 , H 0 A 기각 F B > F ( α ; b − 1 , ( a − 1 ) ( b − 1 ) ) 이면 , H 0 B 기각
\begin{aligned}
F_A &> F_{(\alpha; a-1, (a-1)(b-1))}\, 이면, \,H_{0A}\,기각 \\
F_B &> F_{(\alpha; b-1, (a-1)(b-1))}\, 이면, \,H_{0B}\,기각 \\
\end{aligned}
F A F B > F ( α ; a − 1 , ( a − 1 ) ( b − 1 )) 이면 , H 0 A 기각 > F ( α ; b − 1 , ( a − 1 ) ( b − 1 )) 이면 , H 0 B 기각
11.3.2 반복이 있는 이원배치법
반복이 없는 이원배치법에서는 두 인자의 수준들의 조합에 대해 한번의 실험을 함
가능하다면 2번 이상의 실험을 하는 것이 바람직
본 절에서는 수준조합당 실험 반복을 r번씩 하는 경우를 다룸
반복이 있는 이원배치법에서는 두 인자의 교호작용(interaction)에 대한 분석을 추가로 할 수 있음
반복이 있는 이원배치법의 데이터 구조식은 다음과 같음
Y i j k = μ i j + ε i j k , i = 1 , 2 , … , a ; j = 1 , 2 , … , b ; k = 1 , 2 , … , r μ i j = μ + α i + β j + ( α β ) i j (11.7)
\tag{11.7}
Y_{ijk} = \mu_{ij}+\varepsilon_{ijk}, \,\, i = 1,2,\dots,a; \,\, j=1,2,\dots,b; \,\, k=1,2,\dots,r\\
\mu_{ij} = \mu + \alpha_i + \beta_j +(\alpha\beta)_{ij}
Y ijk = μ ij + ε ijk , i = 1 , 2 , … , a ; j = 1 , 2 , … , b ; k = 1 , 2 , … , r μ ij = μ + α i + β j + ( α β ) ij ( 11.7 )
여기서 μ i j \mu_{ij} μ ij α i \alpha_i α i β j \beta_j β j ( α β i j ) (\alpha\beta_{ij}) ( α β ij )
<표 11-5> 반복이 있는 이원배치법의 데이터 구조
인자 B \ 인자 A A 1 A 2 … A a \begin{matrix}A_1&&&&A_2&&&&\dots&&&&A_a\end{matrix} A 1 A 2 … A a 합 평균 B 1 B_1 B 1 Y 111 Y 112 ⋮ Y 11 r } T 11. Y 211 Y 212 ⋮ Y 21 r } T 21. … … … Y a 11 Y a 12 ⋮ Y a 1 r } T a 1. \begin{matrix}\begin{matrix}Y_{111}\\Y_{112}\\\vdots\\Y_{11r}\end{matrix} \Bigg\}T_{11.}&&\begin{matrix}Y_{211}\\Y_{212}\\\vdots\\Y_{21r}\end{matrix} \Bigg\}T_{21.} &&\begin{matrix}\dots\\\dots\\\\\dots\end{matrix}&& \begin{matrix}Y_{a11}\\Y_{a12}\\\vdots\\Y_{a1r}\end{matrix} \Bigg\}T_{a1.}\end{matrix} Y 111 Y 112 ⋮ Y 11 r } T 11. Y 211 Y 212 ⋮ Y 21 r } T 21. … … … Y a 11 Y a 12 ⋮ Y a 1 r } T a 1. T . 1. T_{.1.} T .1. Y ˉ . 1. \bar Y_{.1.} Y ˉ .1. B 2 B_2 B 2 Y 121 Y 122 ⋮ Y 12 r } T 12. Y 221 Y 222 ⋮ Y 22 r } T 22. … … … Y a 21 Y a 22 ⋮ Y a 2 r } T a 2. \begin{matrix}\begin{matrix}Y_{121}\\Y_{122}\\\vdots\\Y_{12r}\end{matrix} \Bigg\}T_{12.}&&\begin{matrix}Y_{221}\\Y_{222}\\\vdots\\Y_{22r}\end{matrix} \Bigg\}T_{22.} &&\begin{matrix}\dots\\\dots\\\\\dots\end{matrix}&& \begin{matrix}Y_{a21}\\Y_{a22}\\\vdots\\Y_{a2r}\end{matrix} \Bigg\}T_{a2.}\end{matrix} Y 121 Y 122 ⋮ Y 12 r } T 12. Y 221 Y 222 ⋮ Y 22 r } T 22. … … … Y a 21 Y a 22 ⋮ Y a 2 r } T a 2. T . 2. T_{.2.} T .2. Y ˉ . 2. \bar Y_{.2.} Y ˉ .2. ⋮ \vdots ⋮ ⋮ ⋮ ⋮ ⋮ \begin{matrix}\vdots&&&&\vdots&&&&\vdots&&&&\vdots \end{matrix} ⋮ ⋮ ⋮ ⋮ B b B_b B b Y 1 b 1 Y 1 b 2 ⋮ Y 1 b r } T 1 b . Y 2 b 1 Y 2 b 2 ⋮ Y 2 b r } T 2 b . … … … Y a b 1 Y a b 2 ⋮ Y a b r } T a b . \begin{matrix}\begin{matrix}Y_{1b1}\\Y_{1b2}\\\vdots\\Y_{1br}\end{matrix} \Bigg\}T_{1b.}&&\begin{matrix}Y_{2b1}\\Y_{2b2}\\\vdots\\Y_{2br}\end{matrix} \Bigg\}T_{2b.} &&\begin{matrix}\dots\\\dots\\\\\dots\end{matrix}&& \begin{matrix}Y_{ab1}\\Y_{ab2}\\\vdots\\Y_{abr}\end{matrix} \Bigg\}T_{ab.}\end{matrix} Y 1 b 1 Y 1 b 2 ⋮ Y 1 b r } T 1 b . Y 2 b 1 Y 2 b 2 ⋮ Y 2 b r } T 2 b . … … … Y ab 1 Y ab 2 ⋮ Y ab r } T ab . T . b . T_{.b.} T . b . Y ˉ . b . \bar Y_{.b.} Y ˉ . b . 합 T 1.. T 2.. … T a . . \begin{matrix}T_{1..}&&T_{2..}&&\dots&&T_{a..}\end{matrix} T 1.. T 2.. … T a .. T T T 평균 Y ˉ 1.. Y ˉ 2.. … Y ˉ a . . \begin{matrix}\bar Y_{1..}&&\bar Y_{2..}&&\dots&&\bar Y_{a..}\end{matrix} Y ˉ 1.. Y ˉ 2.. … Y ˉ a .. Y ˉ . . . \bar Y_{...} Y ˉ ...
전체 제곱합을 요인별로 분해하기 위해 우선 SST가 다음과 같이 됨을 보일 수 있음
S S T = ∑ i = 1 a ∑ j = 1 b ∑ k = 1 r ( Y i j k − Y ˉ … ) 2 = r ∑ i = 1 a ∑ j = 1 b ( Y ˉ i j . − Y ˉ … ) 2 + ∑ i = 1 a ∑ j = 1 b ∑ k = 1 r ( Y i j k − Y ˉ i j . ) 2 (11.8) \small{SST = \sum_{i=1}^a \sum_{j=1}^b\sum_{k=1}^r(Y_{ijk} - \bar Y_{\dots})^2 = r\sum_{i=1}^a\sum_{j=1}^b(\bar Y_{ij.} - \bar Y_{\dots})^2 + \sum_{i=1}^a\sum_{j=1}^b\sum_{k=1}^r(Y_{ijk}-\bar Y_{ij.})^2} \quad\quad \quad\tag{11.8} SST = i = 1 ∑ a j = 1 ∑ b k = 1 ∑ r ( Y ijk − Y ˉ … ) 2 = r i = 1 ∑ a j = 1 ∑ b ( Y ˉ ij . − Y ˉ … ) 2 + i = 1 ∑ a j = 1 ∑ b k = 1 ∑ r ( Y ijk − Y ˉ ij . ) 2 ( 11.8 )
위 식의 두 번째 항은 오차제곱합을 나타내며, 첫 번째 항은 각 처리조건에 대한 평균과 전체 평균과의 차에 대한 제곱합이므로 이를 처리제곱합 (treatment sum of squares; SSTR)이라 한다
즉,
S S T R = r ∑ i = 1 a ∑ j = 1 b ( Y ˉ i j . − Y ˉ . . . ) 2 (11.9)
\tag{11.9}
SSTR = r\sum_{i=1}^a\sum_{j=1}^b(\bar Y_{ij.}-\bar Y_{...})^2
SSTR = r i = 1 ∑ a j = 1 ∑ b ( Y ˉ ij . − Y ˉ ... ) 2 ( 11.9 ) 따라서 식 11.8의 전체 제곱합은 다음과 같이 분해된다
S S T = S S T R + S S E (11.10)
\tag{11.10}
SST = SSTR + SSE
SST = SSTR + SSE ( 11.10 ) 그리고 식 11.9에 관련관 Y ˉ i j . − Y ˉ . . . \bar Y_{ij.} - \bar Y_{...} Y ˉ ij . − Y ˉ ...
Y ˉ i j . − Y ˉ . . . = [ a 효과 ] ( Y ˉ i . . − Y ˉ . . . ) + [ b 효과 ] ( Y ˉ . j . − Y ˉ . . . ) + [ a 와 b 의 교호작용 ] ( Y ˉ i j . − Y ˉ i . . − Y ˉ . j . + Y ˉ . . . )
\bar Y_{ij.} - \bar Y_{...} = [a\,효과]\,(\bar Y_{i..} - \bar Y_{...}) + [b \,효과]\,(\bar Y_{.j.} - \bar Y_{...}) + [a와\,b의\,교호작용]\,(\bar Y_{ij.} - \bar Y_{i..}-\bar Y_{.j.} + \bar Y_{...})
Y ˉ ij . − Y ˉ ... = [ a 효과 ] ( Y ˉ i .. − Y ˉ ... ) + [ b 효과 ] ( Y ˉ . j . − Y ˉ ... ) + [ a 와 b 의 교호작용 ] ( Y ˉ ij . − Y ˉ i .. − Y ˉ . j . + Y ˉ ... ) 처리제곱합 SSTR은 다음과 같이 인자 A의 제곱합(SSA), 인자 B의 제곱합(SSB), 인자 AB의 교호작용 제곱합(SSAB)로 분해됨
S S T R = S S A + S S B + S S A B (11.11) \tag{11.11}
SSTR = SSA + SSB + SSAB SSTR = SS A + SSB + SS A B ( 11.11 ) 결국 전체제곱합은 다시 다음과 같이 분해된다고 볼 수 있음
S S T = S S A + S S B + S S A B + S S E (11.12)
\tag{11.12}
SST = SSA + SSB + SSAB + SSE
SST = SS A + SSB + SS A B + SSE ( 11.12 ) 각 요인별 제곱합을 산출하기 위해 다음 식들을 이용하면 편리
S S T = ∑ i = 1 a ∑ j = 1 b ∑ k = 1 r Y i j k 2 − C T (11.13a)
\tag{11.13a}
SST = \sum_{i=1}^a\sum_{j=1}^b\sum_{k=1}^rY_{ijk}^2 - CT
SST = i = 1 ∑ a j = 1 ∑ b k = 1 ∑ r Y ijk 2 − CT ( 11.13a ) S S T R = 1 r ∑ i = 1 a ∑ j = 1 b T i j . 2 − C T (11.13b)
\tag{11.13b}
SSTR = \frac{1}{r}\sum_{i=1}^a\sum_{j=1}^bT_{ij.}^2 - CT
SSTR = r 1 i = 1 ∑ a j = 1 ∑ b T ij . 2 − CT ( 11.13b ) S S E = S S T − S S T R (11.13c)
\tag{11.13c}
SSE = SST - SSTR
SSE = SST − SSTR ( 11.13c ) S S A = 1 b r ∑ i = 1 a T i . . 2 − C T (11.13d)
\tag{11.13d}
SSA = \frac{1}{br}\sum_{i=1}^aT_{i..}^2 - CT
SS A = b r 1 i = 1 ∑ a T i .. 2 − CT ( 11.13d ) S S B = 1 a r ∑ j = 1 b T . j . 2 − C T (11.13e)
\tag{11.13e}
SSB = \frac{1}{ar}\sum_{j=1}^bT_{.j.}^2 - CT
SSB = a r 1 j = 1 ∑ b T . j . 2 − CT ( 11.13e ) S S A B = S S T R − S S A − S S B (11.13f)
\tag{11.13f}
SSAB = SSTR - SSA - SSB
SS A B = SSTR − SS A − SSB ( 11.13f ) 여기서 CT는 수정항(correction term)으로 다음과 같이 주어짐
C T = T 2 a b r (11.14)
\tag{11.14}
CT = \frac{T^2}{abr}
CT = ab r T 2 ( 11.14 ) <표 11-6> 반복이 있는 이원배치법의 분산분석표
변동요인 제곱합 자유도 평균제곱 F − F- F − 인자 A S S A SSA SS A a − 1 a-1 a − 1 M S A = S S A / ( a − 1 ) MSA=SSA/(a-1) MS A = SS A / ( a − 1 ) F A = M S A / M S E F_A=MSA/MSE F A = MS A / MSE 인자 B S S B SSB SSB b − 1 b-1 b − 1 M S B = S S B / ( b − 1 ) MSB=SSB/(b-1) MSB = SSB / ( b − 1 ) F B = M S B / M S E F_B=MSB/MSE F B = MSB / MSE 교호작용 S S A B SSAB SS A B ( a − 1 ) ( b − 1 ) (a-1)(b-1) ( a − 1 ) ( b − 1 ) M S A B = S S A B / ( ( a − 1 ) ( b − 1 ) ) MSAB=SSAB/((a-1)(b-1)) MS A B = SS A B / (( a − 1 ) ( b − 1 )) F A B = M S A B / M S E F_{AB}=MSAB/MSE F A B = MS A B / MSE 오차 S S E SSE SSE a b ( r − 1 ) ab(r-1) ab ( r − 1 ) M S E = S S E / ( a b ( r − 1 ) ) MSE=SSE/(ab(r-1)) MSE = SSE / ( ab ( r − 1 )) 전체 S S T SST SST a b − 1 ab-1 ab − 1
각 요인에 대한 가설과 검정방법
인자 A의 효과에 대한 검정H 0 : α 0 = α 2 = ⋯ = α a = 0 H 1 : 모든 α i 가 0 은 아니다 . (11.15)
\tag{11.15}
\begin{aligned}
H_0 &: \alpha_0 = \alpha_2 = \dots = \alpha_a = 0 \\
H_1 &: 모든\,\,\alpha_i가\,\,0은\,\,아니다.
\end{aligned}
H 0 H 1 : α 0 = α 2 = ⋯ = α a = 0 : 모든 α i 가 0 은 아니다 . ( 11.15 ) 검정통계량 $F_A = MSA/MSE의 값이 F ( α ; a − 1 , a b ( r − 1 ) ) F_{(\alpha;\,a-1,ab(r-1))} F ( α ; a − 1 , ab ( r − 1 ))
인자 B의 효과에 대한 검정H 0 : β 0 = β 2 = ⋯ = β b = 0 H 1 : 모든 β i 가 0 은 아니다 . (11.16)
\tag{11.16}
\begin{aligned}
H_0 &: \beta_0 = \beta_2 = \dots = \beta_b = 0 \\
H_1 &: 모든\,\,\beta_i가\,\,0은\,\,아니다.
\end{aligned}
H 0 H 1 : β 0 = β 2 = ⋯ = β b = 0 : 모든 β i 가 0 은 아니다 . ( 11.16 ) 검정통계량 F B = M S B / M S E F_B = MSB/MSE F B = MSB / MSE F ( α ; b − 1 , a b ( r − 1 ) ) F_{(\alpha;\,b-1,ab(r-1))} F ( α ; b − 1 , ab ( r − 1 ))
교호작용에 대한 검정H 0 : ( α β ) i j = 0 ( 모든 i 와 j 에 대해 ) H 1 : 모든 ( α β ) i j 가 0 은 아니다 . (11.17)
\tag{11.17}
\begin{aligned}
H_0 &: (\alpha\beta){ij} = 0\,\,(모든\,i와\,j에\,대해) \\
H_1 &: 모든\,\,(\alpha\beta){ij}가\,\,0은\,\,아니다.
\end{aligned}
H 0 H 1 : ( α β ) ij = 0 ( 모든 i 와 j 에 대해 ) : 모든 ( α β ) ij 가 0 은 아니다 . ( 11.17 ) 검정통계량 F A B = M S A B / M S E F_{AB} = MSAB/MSE F A B = MS A B / MSE F ( α ; ( a − 1 ) ( b − 1 ) , a b ( r − 1 ) ) F_{(\alpha; (a-1)(b-1), ab(r-1))} F ( α ; ( a − 1 ) ( b − 1 ) , ab ( r − 1 )) → \rarr →
반복이 있는 이원배치법에서는 우선 인자간의 교호작용이 있는가를 검정하고 교호작용이 유의하지 않은 경우에는 교호작용을 오차항과 합하여 풀링한 오차제곱합을 이용하여 검정할 수 있음
표 11-4와 표 11-6에서 반복이 없는 경우 (r=1)은 원래 오차항의 자유도는 0이 되는데 교호작용의 제곱합을 오차의 제곱합으로 간주한 것
또한 반복이 없는 이원배치법에 대해서도 r=1로 놓고 식 11.13과 식 11.14를 적용하여 제곱합을 산출할 수 있음
단, 반복이 없는 실험에서는 그 실험에서의 최고차 교호작용(여기서는 SSAB)를 오차(SSE)로 간주
11.4 요인배치법
인자의 수가 n n n k k k k n k^n k n 2 3 2^3 2 3 3 2 3^2 3 2
요인배치법은 모든 인자의 주효과뿐만 아니라 모든 가능한 교호작용을 검정하고자 할 때 효과적
요인배치법은 다원배치법의 특수한 형태인데 그 분석방법이 단순하기 때문에 널리 사용
그러나 요인의 수가 많은 경우에는 실험조건이 많아지므로 시간 및 비용의 고려도 필요
11.4.2 2 2 2^2 2 2
2 2 2^2 2 2
Y i j k = μ i j + ε i j k , i = 0 , 1 ; j = 0 , 1 ; k = 1 , 2 , … , r μ i j = μ + α i + β j + ( α β ) i j (11.18)
\tag{11.18}
\begin{aligned}
Y_{ijk} &= \mu_{ij} + \varepsilon_{ijk},\,\,i=0,1;\,j=0,1;\,k=1,2,\dots,r \\
\mu_{ij} &= \mu + \alpha_i + \beta_j + (\alpha\beta)_{ij}
\end{aligned}
Y ijk μ ij = μ ij + ε ijk , i = 0 , 1 ; j = 0 , 1 ; k = 1 , 2 , … , r = μ + α i + β j + ( α β ) ij ( 11.18 ) 각 인자가 두 수준을 갖기 때문에 편의상 첫 수준을 0, 두번째 수준을 1로 나타냄
인자 A의 i 수준에서의 평균을 μ i . \mu_i. μ i . μ . j \mu_{.j} μ . j
μ i . = μ + α i μ . j = μ + β j
\mu_{i.} = \mu + \alpha_i \\
\mu_{.j} = \mu + \beta_j
μ i . = μ + α i μ . j = μ + β j 식 11.18의 μ i j \mu_{ij} μ ij
μ i j = μ i . + μ . j − μ + ( α β ) i j (11.19)
\tag{11.19}
\mu_{ij} = \mu_{i.} + \mu_{.j} - \mu + (\alpha\beta)_{ij}
μ ij = μ i . + μ . j − μ + ( α β ) ij ( 11.19 ) 전체 데이터 구조는 표 11.7과 같다
<표 11.7> 2 2 2^2 2 2 요인배치법의 데이터 구조
$A_0$ A 1 A_1 A 1 합 B 0 B_0 B 0 Y 001 ⋮ Y 00 r } T 00. \begin{matrix}Y_{001}\\\vdots\\Y_{00r}\end{matrix}\Big\}T_{00.} Y 001 ⋮ Y 00 r } T 00. Y 101 ⋮ Y 10 r } T 10. \begin{matrix}Y_{101}\\\vdots\\Y_{10r}\end{matrix}\Big\}T_{10.} Y 101 ⋮ Y 10 r } T 10. T . 0. T_{.0.} T .0. B 1 B_1 B 1 Y 011 ⋮ Y 01 r } T 01. \begin{matrix}Y_{011}\\\vdots\\Y_{01r}\end{matrix}\Big\}T_{01.} Y 011 ⋮ Y 01 r } T 01. Y 111 ⋮ Y 11 r } T 11. \begin{matrix}Y_{111}\\\vdots\\Y_{11r}\end{matrix}\Big\}T_{11.} Y 111 ⋮ Y 11 r } T 11. T . 1. T_{.1.} T .1. 합계 T 0.. T_{0..} T 0.. T 1.. T_{1..} T 1.. T T T
분석방법은 11.3.2절의 반복이 있는 이원배치법과 동일한 방식을 이용할 수 있지만 아래 결과를 이용하면 보다 간단하게 각 요인의 제곱합을 구할 수 있음
인자 A의 주효과는 수준 A 1 A_1 A 1 A 0 A_0 A 0
인자 A 주효과 = μ 1. − μ 0. = α 1 − α 0
인자\,\,A\,\,주효과 = \mu_{1.} - \mu_{0.} = \alpha_{1} - \alpha_{0}
인자 A 주효과 = μ 1. − μ 0. = α 1 − α 0 다음 식으로 추정 가능
A 주효과 = 1 2 r [ T 1.. − T 0.. ] (11.20) \tag{11.20}
A\,\,주효과 = \frac{1}{2r}[T_{1..} - T_{0..}]
A 주효과 = 2 r 1 [ T 1.. − T 0.. ] ( 11.20 ) 식 11.20에서 μ i . \mu_{i.} μ i . T i . . / 2 r T_{i..}/2r T i .. /2 r μ . 1 − μ . 0 = β 1 − β 0 \mu_{.1} - \mu_{.0} = \beta_1 - \beta_0 μ .1 − μ .0 = β 1 − β 0
B 주효과 = 1 2 r [ T . 1. − T . 0. ] (11.21)
\tag{11.21}
B \,\, 주효과 = \frac{1}{2r}[T_{.1.} - T_{.0.}]
B 주효과 = 2 r 1 [ T .1. − T .0. ] ( 11.21 ) 인자 간의 교호작용이 있다는 것은 수준 A 1 A_1 A 1 A 0 A_0 A 0 → \rarr →
A B 교호작용 = ( μ 11 − μ 10 ) − ( μ 01 − μ 00 ) 2 = { ( α β ) 11 − ( α β ) 10 } − { ( α β ) 01 − ( α β ) 00 } 2
AB\,교호작용 = \frac{(\mu_{11}-\mu_{10})-(\mu_{01}-\mu_{00})}{2} = \frac{\{(\alpha\beta){11}-(\alpha\beta){10}\} - \{(\alpha\beta){01}-(\alpha\beta){00}\}}{2}
A B 교호작용 = 2 ( μ 11 − μ 10 ) − ( μ 01 − μ 00 ) = 2 {( α β ) 11 − ( α β ) 10 } − {( α β ) 01 − ( α β ) 00 } 따라서 아래와 같이 추정할 수 있다
A B 교호작용 = 1 2 r [ ( T 11. − T 10. ) − ( T 01. − T 00. ) ] = 1 2 r [ T 11. + T 00. − T 10. − T 01. ] (11.22)
\tag{11.22}
\begin{aligned}
AB \,\, 교호작용 &= \frac{1}{2r}[(T_{11.} - T_{10.}) - (T_{01.} - T_{00.})] \\
&= \frac{1}{2r}[T_{11.} + T_{00.} - T_{10.} - T_{01.}]
\end{aligned}
A B 교호작용 = 2 r 1 [( T 11. − T 10. ) − ( T 01. − T 00. )] = 2 r 1 [ T 11. + T 00. − T 10. − T 01. ] ( 11.22 ) 각 요인에 대한 제곱합은 위에서 계산된 각 효과의 제곱에 $r$을 곱합으로써 다음과 같이 산출된다
S S A = r ( A 주효과 ) 2 = 1 4 r ( T 1.. − T 0.. ) 2 (11.23a)
\tag{11.23a}
SSA = r(A 주효과)^2 = \frac{1}{4r}(T_{1..} - T_{0..})^2
SS A = r ( A 주효과 ) 2 = 4 r 1 ( T 1.. − T 0.. ) 2 ( 11.23a ) S S B = r ( B 주효과 ) 2 = 1 4 r ( T . 1. − T . 0. ) 2 (11.23b)
\tag{11.23b}
SSB = r(B 주효과)^2 = \frac{1}{4r}(T_{.1.} - T_{.0.})^2
SSB = r ( B 주효과 ) 2 = 4 r 1 ( T .1. − T .0. ) 2 ( 11.23b ) S S A B = r ( A B 교호작용 ) 2 (11.23c) \tag{11.23c}
SSAB = r(AB교호작용)^2
SS A B = r ( A B 교호작용 ) 2 ( 11.23c ) 위 식에서 분모의 4 r 4r 4 r
전체제곱합 SST는 다음식으로부터 산출됨
S S T = ∑ i = 0 1 ∑ j = 0 1 ∑ k = 1 r Y i j k 2 − T 2 4 r (11.24)
\tag{11.24}
SST = \sum_{i=0}^1\sum_{j=0}^1\sum_{k=1}^rY_{ijk}^2 -\frac{T^2}{4r}
SST = i = 0 ∑ 1 j = 0 ∑ 1 k = 1 ∑ r Y ijk 2 − 4 r T 2 ( 11.24 ) 따라서 오차제곱합은 아래와 같다
S S E = S S T − ( S S A + S S B + S S A B )
SSE = SST - (SSA + SSB + SSAB)
SSE = SST − ( SS A + SSB + SS A B ) <표 11.8> 2 2 2^2 2 2 요인배치법의 분산분석표
변동요인 제곱합 자유도 평균제곱 F − F- F − A S S A SSA SS A 1 M S A = S S A / 1 MSA=SSA/1 MS A = SS A /1 F A = M S A / M S E F_A = MSA/MSE F A = MS A / MSE B S S B SSB SSB 1 M S B = S S B / 1 MSB=SSB/1 MSB = SSB /1 F B = M S B / M S E F_B = MSB/MSE F B = MSB / MSE AB S S A B SSAB SS A B 1 M S A B = S S A B / 1 MSAB=SSAB/1 MS A B = SS A B /1 F A B = M S A B / M S E F_{AB} = MSAB/MSE F A B = MS A B / MSE 오차 S S E SSE SSE 4 ( r − 1 ) 4(r-1) 4 ( r − 1 ) M S E = S S E / ( 4 ( r − 1 ) ) MSE=SSE/(4(r-1)) MSE = SSE / ( 4 ( r − 1 )) 전체 S S T SST SST 4 r − 1 4r-1 4 r − 1
인자 A의 효과, 인자 B의 효과, 교호작용에 대한 검정은 각각 식 11.15, 11.16, 11.17과 같으며 검정과정은 반복이 없는 이원배치법의 경우와 동일
각 수준 조합 내 반복이 없는 경우 교호작용과 오차를 서로 분리하여 검출할 수 없으며 따라서 주효과에 대한 검정만 가능
11.4.2 2 3 2^3 2 3
2 3 2^3 2 3
반복수가 r일 때 모형은 다음과 같다
Y i j k m = μ + α i + β j + γ k + ( α β ) i j + ( β γ ) j k + ( α γ ) i k + ( α β γ ) i j k + ε i j k m , ( i , j , k = 0 , 1 ; m = 1 , 2 , … , r ) (11.25) \small{
Y_{ijkm} = \mu + \alpha_i + \beta_j + \gamma_k + (\alpha\beta){ij} + (\beta\gamma){jk} + (\alpha\gamma){ik} + (\alpha\beta\gamma){ijk} + \varepsilon_{ijkm}, \\
(i,j,k = 0,1;\,\,m=1,2,\dots,r)}\\
\quad\quad \tag{11.25}
Y ijkm = μ + α i + β j + γ k + ( α β ) ij + ( β γ ) jk + ( α γ ) ik + ( α β γ ) ijk + ε ijkm , ( i , j , k = 0 , 1 ; m = 1 , 2 , … , r ) ( 11.25 ) 여기서 γ k \gamma_k γ k ( β γ ) j k (\beta\gamma){jk} ( β γ ) jk 는 인자 B와 C의 교호작용, ( α β γ ) i j k (\alpha\beta\gamma){ijk} ( α β γ ) ijk
각 인자의 첫 수준을 0, 두 번째 수준을 1로 나타내면 각 실험처리조합의 데이터합은 표 11.9와 같이 나타낼 수 있다
<표 11.9> 2 3 2^3 2 3 요인배치법의 데이터 구조
A 0 A_0 A 0 A 1 A_1 A 1 합 B 0 B_0 B 0 C 0 C 1 \begin{matrix}C_0\\C_1\end{matrix} C 0 C 1 T 000 T 001 } T 00. \begin{matrix}T_{000}\\T_{001}\end{matrix}\Big\}T_{00.} T 000 T 001 } T 00. T 100 T 101 } T 10. \begin{matrix}T_{100}\\T_{101}\end{matrix}\Big\}T_{10.} T 100 T 101 } T 10. T . 0. T_{.0.} T .0. B 1 B_1 B 1 C 0 C 1 \begin{matrix}C_0\\C_1\end{matrix} C 0 C 1 T 010 T 011 } T 01. \begin{matrix}T_{010}\\T_{011}\end{matrix}\Big\}T_{01.} T 010 T 011 } T 01. T 110 T 111 } T 11. \begin{matrix}T_{110}\\T_{111}\end{matrix}\Big\}T_{11.} T 110 T 111 } T 11. T . 1. T_{.1.} T .1. 합계 T 0.. T_{0..} T 0.. T 1.. T_{1..} T 1.. T T T
A 주효과 = 1 4 r [ T 1.. − T 0.. ] (11.26a)
\tag{11.26a}
A 주효과 = \frac{1}{4r}[T_{1..}-T_{0..}] A 주효과 = 4 r 1 [ T 1.. − T 0.. ] ( 11.26a ) C 주효과 = 1 4 r [ T . . 1 − T . . 0 ] (11.26c)
\tag{11.26c}
C 주효과 = \frac{1}{4r}[T_{..1}-T_{..0}]
C 주효과 = 4 r 1 [ T ..1 − T ..0 ] ( 11.26c ) 2 3 2^3 2 3
A B 교호작용 = 1 4 r [ T 11. + T 00. − T 10. − T 01. ] (11.27a)
\tag{11.27a}
AB\,\,교호작용 = \frac{1}{4r}[T_{11.}+T_{00.}-T_{10.}-T_{01.}]
A B 교호작용 = 4 r 1 [ T 11. + T 00. − T 10. − T 01. ] ( 11.27a ) A C 교호작용 = 1 4 r [ T 1.1 + T 0.0 − T 0.1 − T 1.0 ] (11.27b)
\tag{11.27b}
AC\,\,교호작용 = \frac{1}{4r}[T_{1.1}+T_{0.0}-T_{0.1}-T_{1.0}]
A C 교호작용 = 4 r 1 [ T 1.1 + T 0.0 − T 0.1 − T 1.0 ] ( 11.27b ) B C 교호작용 = 1 4 r [ T . 11 + T . 00 − T . 10 − T . 01 ] (11.27c)
\tag{11.27c}
BC\,\,교호작용 = \frac{1}{4r}[T_{.11}+T_{.00}-T_{.10}-T_{.01}]
BC 교호작용 = 4 r 1 [ T .11 + T .00 − T .10 − T .01 ] ( 11.27c ) ABC 3차 교호작용은 다음과 같이 얻을 수 있음
ABC의 3차 교호작용은 B 1 B_1 B 1 B 0 B_0 B 0 B 1 B_1 B 1 ( T 111 − T 110 ) − ( T 011 − T 010 ) (T_{111} - T_{110}) - (T_{011} - T_{010}) ( T 111 − T 110 ) − ( T 011 − T 010 ) B 0 B_0 B 0 ( T 101 − T 100 ) − ( T 001 − T 000 ) (T_{101}-T_{100}) - (T_{001}-T_{000}) ( T 101 − T 100 ) − ( T 001 − T 000 )
A B C 교호작용 = 1 4 r [ ( T 111 − T 110 ) − ( T 011 − T 010 ) − { ( T 101 − T 100 ) − ( T 001 − T 000 ) } ] = 1 4 r [ T 111 + T 100 + T 010 + T 001 ) − T 011 − T 101 − T 110 − T 000 ] (11.28)
\tag{11.28}
\begin{aligned}
ABC\,\,교호작용 &= \frac{1}{4r}[(T_{111} - T_{110}) - (T_{011} - T_{010}) - \{(T_{101}-T_{100}) - (T_{001}-T_{000})\}] \\
&= \frac{1}{4r}[T_{111} + T_{100} + T_{010} + T_{001}) - T_{011}-T_{101} - T_{110}-T_{000}]
\end{aligned}
A BC 교호작용 = 4 r 1 [( T 111 − T 110 ) − ( T 011 − T 010 ) − {( T 101 − T 100 ) − ( T 001 − T 000 )}] = 4 r 1 [ T 111 + T 100 + T 010 + T 001 ) − T 011 − T 101 − T 110 − T 000 ] ( 11.28 )
각 인자의 제곱합 및 인자들의 교호작용에 대한 제곱합은 다음과 같은 방식으로 산출된다
S S A = 2 r ( A 주효과 ) 2 = 1 8 r ( T 1.. − T . . . ) 2 (11.29a)
\tag{11.29a}
SSA = 2r(A주효과)^2 = \frac{1}{8r}(T_{1..}-T_{...})^2
SS A = 2 r ( A 주효과 ) 2 = 8 r 1 ( T 1.. − T ... ) 2 ( 11.29a ) S S B = 2 r ( B 주효과 ) 2 = 1 8 r ( T . 1. − T . 0. ) 2 (11.29b)
\tag{11.29b}
SSB = 2r(B주효과)^2 = \frac{1}{8r}(T_{.1.}-T_{.0.})^2
SSB = 2 r ( B 주효과 ) 2 = 8 r 1 ( T .1. − T .0. ) 2 ( 11.29b ) S S C = 2 r ( C 주효과 ) 2 = 1 8 r ( T . . 1 − T . . 0 ) 2 (11.29c)
\tag{11.29c}
SSC = 2r(C주효과)^2 = \frac{1}{8r}(T_{..1}-T_{..0})^2
SSC = 2 r ( C 주효과 ) 2 = 8 r 1 ( T ..1 − T ..0 ) 2 ( 11.29c ) S S A B = 2 r ( A B 교호작용 ) 2 (11.29d)
\tag{11.29d}
SSAB = 2r(AB교호작용)^2
SS A B = 2 r ( A B 교호작용 ) 2 ( 11.29d ) S S A C = 2 r ( A C 교호작용 ) 2 (11.29e)
\tag{11.29e}
SSAC = 2r(AC교호작용)^2
SS A C = 2 r ( A C 교호작용 ) 2 ( 11.29e ) S S B C = 2 r ( B C 교호작용 ) 2 (11.29f)
\tag{11.29f}
SSBC = 2r(BC교호작용)^2
SSBC = 2 r ( BC 교호작용 ) 2 ( 11.29f ) S S A B C = 2 r ( A B C 교호작용 ) 2 (11.29g)
\tag{11.29g}
SSABC = 2r(ABC교호작용)^2
SS A BC = 2 r ( A BC 교호작용 ) 2 ( 11.29g ) 위 식에서 분모의 8 r 8r 8 r
전체제곱합은 다음과 같이 계산됨
S S T = ∑ i = 0 1 ∑ j = 0 1 ∑ k = 0 1 ∑ m = 1 r Y i j k m 2 − T 2 8 r (11.30)
\tag{11.30}
SST = \sum_{i=0}^1\sum_{j=0}^1\sum_{k=0}^1\sum_{m=1}^r Y_{ijkm}^2 - \frac{T^2}{8r}
SST = i = 0 ∑ 1 j = 0 ∑ 1 k = 0 ∑ 1 m = 1 ∑ r Y ijkm 2 − 8 r T 2 ( 11.30 )
위의 결과로부터 얻은 분산분석표는 다음과 같다
<표 11.10> 2 3 2^3 2 3 요인배치법의 분산분석표
변동요인 제곱합 자유도 평균제곱 F − F- F − A S S A SSA SS A 1 M S A = S S A / 1 MSA = SSA/1 MS A = SS A /1 F A = M S A / M S E F_A=MSA/MSE F A = MS A / MSE B S S B SSB SSB 1 M S B = S S B / 1 MSB = SSB/1 MSB = SSB /1 F B = M S B / M S E F_B=MSB/MSE F B = MSB / MSE C S S C SSC SSC 1 M S C = S S C / 1 MSC = SSC /1 MSC = SSC /1 F C = M S C / M S E F_C=MSC/MSE F C = MSC / MSE AB S S A B SSAB SS A B 1 M S A B = S S A B / 1 MSAB = SSAB /1 MS A B = SS A B /1 F A B = M S A B / M S E F_{AB}=MSAB/MSE F A B = MS A B / MSE AC S S A C SSAC SS A C 1 M S A C = S S S A C / 1 MSAC = SSSAC /1 MS A C = SSS A C /1 F A C = M S A C / M S E F_{AC} = MSAC/MSE F A C = MS A C / MSE BC S S B C SSBC SSBC 1 M S B C = S S B C / 1 MSBC = SSBC /1 MSBC = SSBC /1 F B C = M S B C / M S E F_{BC}=MSBC/MSE F BC = MSBC / MSE ABC S S A B C SSABC SS A BC 1 M S A B C = S S A B C / 1 MSABC = SSABC /1 MS A BC = SS A BC /1 F A B C = M S A B C / M S E F_{ABC}=MSABC/MSE F A BC = MS A BC / MSE 오차 S S E SSE SSE 8 ( r − 1 ) 8(r-1) 8 ( r − 1 ) M S E = S S E / ( 8 ( r − 1 ) ) MSE=SSE/(8(r-1)) MSE = SSE / ( 8 ( r − 1 )) 전체 S S T SST SST 8 r − 1 8r-1 8 r − 1
분석방법은 2 2 2^2 2 2
수준수가 2이고 인자수가 n n n 2 n 2^n 2 n
요인배치법에서 인자의 수 또는 수준수가 증가하면 필요한 실험수는 급격하게 증가함
이 경우 일부 고차의 교호작용을 무시할 수 있다면 교락법(confounding method)을 이용하여 전체 실험처리 중 일부 실험만을 하는 일부실시법을 채택할수도 있음
교락법은 실험전체를 몇 개의 블럭으로 나누는 방법이고 일부실시법은 나누어진 블럭 중 하나를 택하여 실험하는 방법
11.5 수준조합 모평균의 추정
지금까지 주로 분산분석법을 통해 각 인자의 유의성을 검정
본 절에서는 대표적으로 반복이 있는 이원배치법에 대해 수준조합에 대한 모평균을 추정
즉, 인자 A와 B의 ( A i , B j ) (A_i, B_j) ( A i , B j )
특히 ( A i , B j ) (A_i, B_j) ( A i , B j )
식 11.7로 주어진 반복이 있는 이원배치법에 대한 모형을 다시 쓰면 다음과 같다
Y i j k = μ i j + ε i j k , i = 1 , 2 , … , a ; j = 1 , 2 , … , b ; k = 1 , 2 , … , r μ i j = μ + α i + β j + ( α β ) i j
Y_{ijk} = \mu_{ij}+\varepsilon_{ijk}, \,\, i = 1,2,\dots,a; \,\, j=1,2,\dots,b; \,\, k=1,2,\dots,r\\
\mu_{ij} = \mu + \alpha_i + \beta_j +(\alpha\beta)_{ij}
Y ijk = μ ij + ε ijk , i = 1 , 2 , … , a ; j = 1 , 2 , … , b ; k = 1 , 2 , … , r μ ij = μ + α i + β j + ( α β ) ij 위 식에서 μ i j \mu_{ij} μ ij
11.5.1 교호작용이 무시되지 않는 경우
이 경우 μ i j \mu_{ij} μ ij ( A i , B j ) (A_i, B_j) ( A i , B j )
μ ^ i j = T i j . r = Y ^ i j .
\hat \mu_{ij} = \frac{T_{ij.}}{r} = \hat Y_{ij.}
μ ^ ij = r T ij . = Y ^ ij . 이 추정량의 분산은 아래와 같은데
V a r [ μ ^ i j ] = V a r [ T i j . ] r 2 = σ 2 r
Var[\hat \mu_{ij}] = \frac{Var[T_{ij.}]}{r^2} = \frac{\sigma^2}{r}
Va r [ μ ^ ij ] = r 2 Va r [ T ij . ] = r σ 2 여기서 σ 2 \sigma^2 σ 2 μ i j \mu_{ij} μ ij 100 ( 1 − α ) % 100(1-\alpha)\% 100 ( 1 − α ) %
Y ˉ i j . ± t ( α / 2 ; ϕ E ) M S E / r (11.31)
\tag{11.31}
\bar Y_{ij.} \pm t_{(\alpha/2;\phi_E)}\sqrt{MSE/r}
Y ˉ ij . ± t ( α /2 ; ϕ E ) MSE / r ( 11.31 ) 위 식에서 ϕ E \phi_E ϕ E ϕ E = a b ( r − 1 ) \phi_E = ab(r-1) ϕ E = ab ( r − 1 )
11.5.2 교호작용이 무시되는 경우
교호작용이 유의하지 않아 무시되는 경우에는 평균의 추정방법이 약간 다름
이 경우 μ i j \mu_{ij} μ ij
μ i j = μ + α i + β j = μ + α i + μ + β j − μ
\mu_{ij} = \mu + \alpha_i + \beta_j = \mu + \alpha_i + \mu + \beta_j - \mu
μ ij = μ + α i + β j = μ + α i + μ + β j − μ 여기서 μ + α i \mu + \alpha_i μ + α i A i A_i A i μ + β j \mu + \beta_j μ + β j B j B_j B j μ i j \mu_{ij} μ ij
μ ^ i j = Y ˉ i . . + Y ˉ . j . − Y ˉ . . . \hat \mu_{ij} = \bar Y_{i..} + \bar Y_{.j.} - \bar Y_{...}
μ ^ ij = Y ˉ i .. + Y ˉ . j . − Y ˉ ...
이 점추정량의 분산은 아래와 같음을 증명할 수 있음
V a r [ μ ^ i j ] = σ 2 ( 1 b r + 1 a r − 1 a b r ) (11.32)
\tag{11.32}
Var[\hat \mu_{ij}] = \sigma^2(\frac{1}{br} + \frac{1}{ar} - \frac{1}{abr})
Va r [ μ ^ ij ] = σ 2 ( b r 1 + a r 1 − ab r 1 ) ( 11.32 ) 이 때 n e n_e n e
1 n e = 1 a r + 1 b r − 1 a b r = a + b − 1 a b r (11.33)
\tag{11.33}
\frac{1}{n_e} = \frac{1}{ar} + \frac{1}{br} - \frac{1}{abr}=\frac{a+b-1}{abr}
n e 1 = a r 1 + b r 1 − ab r 1 = ab r a + b − 1 ( 11.33 )
식 11.32는 다음과 같이 표현된다
V a r [ μ ^ i j ] = σ 2 n e (11.34)
\tag{11.34}
Var[\hat \mu_{ij}] = \frac{\sigma^2}{n_e}
Va r [ μ ^ ij ] = n e σ 2 ( 11.34 ) 따라서 식 11.34에서 σ 2 \sigma^2 σ 2 μ i j \mu_{ij} μ ij 100 ( 1 − α ) % 100(1-\alpha)\% 100 ( 1 − α ) %
Y ˉ i . . + Y ˉ . j . − Y ˉ . . . ± t ( α / 2 ; ϕ E ) M S E / n e (11.35)
\tag{11.35}
\bar Y_{i..} + \bar Y_{.j.} - \bar Y_{...} \pm t_{(\alpha/2;\phi_E)}\sqrt{MSE/n_e}
Y ˉ i .. + Y ˉ . j . − Y ˉ ... ± t ( α /2 ; ϕ E ) MSE / n e ( 11.35 )
위 식에서 ϕ E \phi_E ϕ E ϕ E = a b ( r − 1 ) \phi_E = ab(r-1) ϕ E = ab ( r − 1 )
식 11.35는 반복이 없는 이원배치법의 경우에도 r=1을 대입하여 적용할 수 있음
단, 오차제곱합의 자유도는 ϕ E = ( a − 1 ) ( b − 1 ) \phi_E = (a-1)(b-1) ϕ E = ( a − 1 ) ( b − 1 )
Uploaded by N2T